Datenflut herauszufiltern und die Renditetreiber zu identifizieren, anhand derer sich künftige Kursentwicklungen abschätzen lassen. Big-Data-Technologien haben in der Finanzbranche ein grosses Potenzial, da Computeralgorithmen sich ideal dafür eignen, riesige Datenmengen zu verarbeiten und mit hoher Geschwindigkeit Muster in Datensätzen zu erkennen.
Deriving insights from data
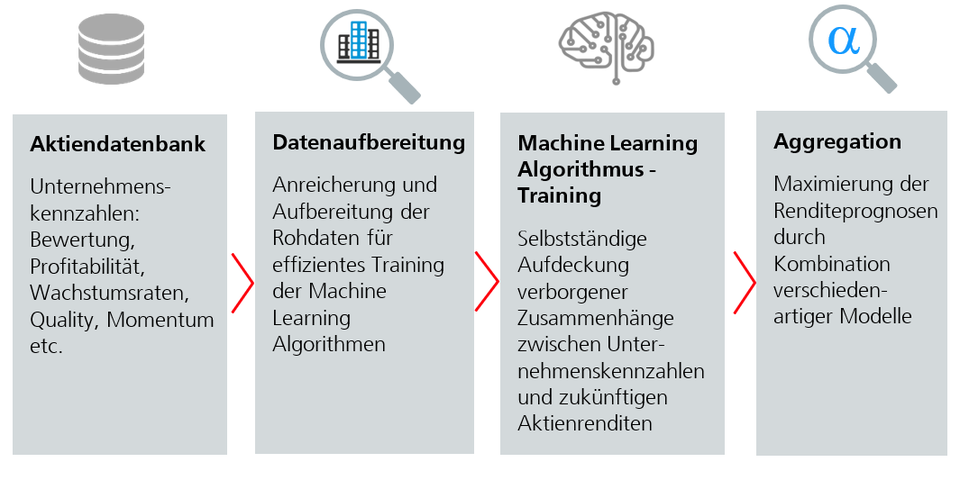
Modernste Machine-Learning-Algorithmen sind in der Lage, Finanzmarktdaten selbstständig zu durchforsten und ohne menschliche Hilfestellung verborgene Zusammenhänge zwischen Unternehmenskennzahlen und zukünftigen Renditen aufzudecken. Dieser Prozess kann in vier Schritte unterteilt werden:
- Aktiendatenbank
Die Grundlage für alle maschinellen Lernalgorithmen bilden umfangreiche Datenbanken mit einer jahrzehntelangen Historie aller Aktien weltweit und allen verfügbaren Unternehmensdaten (Bewertung, Profitabilität, Wachstum, Analystenschätzungen, Risikokennzahlen, Momentum etc.). Je mehr Daten der Lernalgorithmus für das Training zur Verfügung hat, desto besser und stabiler werden die erzielten Renditevorhersagen.
- Datenaufbereitung
Damit die Algorithmen effizient lernen können, werden die Rohdaten in der Regel mit ergänzenden Kennzahlen angereichert und zusätzlich aufbereitet. Dies kann beispielsweise durch Transformation oder Neutralisation der Daten geschehen.
- Training der Machine-Learning-Algorithmen
In diesem Schritt lernt der Algorithmus selbstständig aus den aufbereiteten Daten. Er analysiert, welche Kombination von Unternehmenskennzahlen zu überdurchschnittlichen Renditen führen und ermittelt Eigenheiten von Aktien mit schwacher Performance. Aus diesen Erkenntnissen leitet der Algorithmus dann automatisch komplexe Modelle ab, mit denen sich die zukünftigen Kursentwicklungen aller Aktien weltweit schätzen lassen. Für Menschen sind derart umfangreiche Prognosen kaum möglich, da eine grosse Zahl von Analysten nötig wäre, um tägliche Renditeprognosen für Tausende von Aktien zu erstellen.
- Aggregation
Um die Eintrittswahrscheinlich der Renditeprognosen weiter zu erhöhen, werden verschiedenartige Algorithmen kombiniert. So können Modelle verknüpft werden, die auf kurzfristige (taktische) und langfristige (strategische) Prognosen spezialisiert sind oder ihre Stärke in aufwärts oder abwärts tendierenden Märkten haben. Die dynamische Aggregation verschiedenartiger Prognosemodelle führt zu stabileren und zuverlässigeren Vorhersagen.
Künstliche Intelligenz - Innovative Technologie für die Geldanlage
Auf Machine-Learning-Algorithmen basierende Aktienstrategien erschliessen Alpha-Quellen, die dem Menschen aufgrund ihrer hohen Komplexität bisher verborgen waren. Diese Strategien passen sich schnell und dynamisch an sich verändernde Marktbedingungen an und können auch in schwierigen Phasen - wie der IT-Blase, der Finanzkrise oder der Corona-Pandemie - Mehrrenditen erzielen. Die im Rahmen von Backtests ermittelten Überschussrenditen sind vielversprechend und zudem nur wenig korreliert mit den Renditen traditioneller Aktienfonds, welche einen fundamentalen Ansatz verfolgen. Im Vergleich zu systematischen Anlagestrategien, die meist permanente Stilausrichtungen wie Value oder Quality haben, weisen Strategien, die auf Machine Learning basieren, keine dauerhaften Stilwetten auf.
Bisher gibt es nur wenige öffentlich zugängliche Aktienprodukte, die maschinelle Lernalgorithmen für die Aktienauswahl nutzen. Im Herbst 2021 kam eine Anlagelösung hinzu: Die Zürcher Kantonalbank hat erstmals Artificial-Intelligence-Equity-Zertifikate emittiert, deren Auswahlprozess vollumfänglich auf künstlicher Intelligenz basiert. Mit dieser Innovation ist der Zugang zu den bisher verborgenen Alpha-Quellen für alle Anlegenden offen.